一、环境介绍
由于没钱买显卡,所以在这里我使用AutoDL平台租用的一个3090ti 24G显卡,具体配置如下图

二、模型下载
1. 网站下载(选其一)下载方式 1
模型下载这里就离不开一个网站huggingface,这个网站具体有什么其他用处,可以自己去了解一下。这里我们只需要知道,需要使用它下载一个基座模型。
下载模型我们可以进入huggingface然后搜索自己需要下载的模型,然后点击file吧里面的文件挨个下载下来后,放在同一个文件夹下。
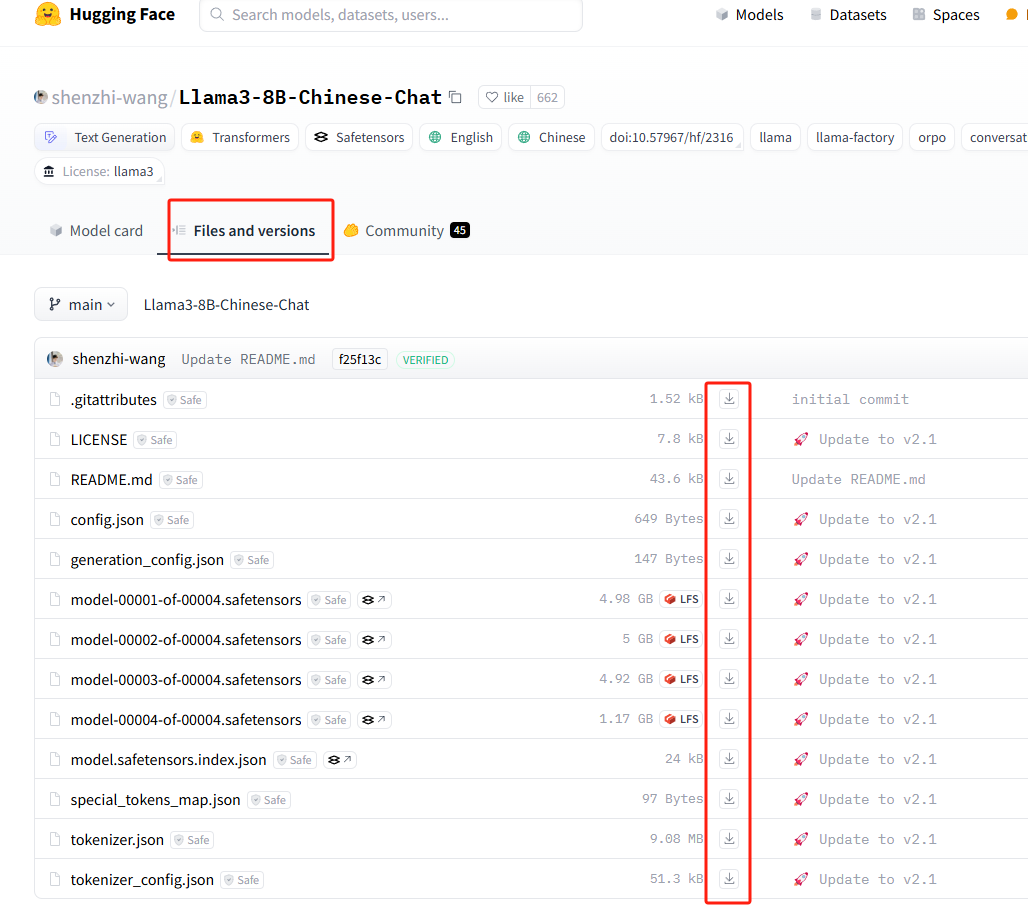
2. 命令下载(选其一)下载方式 2 (推荐使用)
显然挨个点击下砸不太优雅,这里还提供了一个下载工具可以直接在shell中下载模型
第一步安装huggingface工具
pip install -U huggingface_hub由于huggingface被墙了,无法直接使用,这里我们给这个工具换一个国内的代理网站用于下载模型
export HF_ENDPOINT=https://hf-mirror.com使用命令下载基座模型
huggingface-cli download --resume-download shenzhi-wang/Llama3-8B-Chinese-Chat --local-dir /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1三、llama-factory安装
1. llama-factory的官网
进入llama-factory的github链接可以看到这个工具详细的介绍和教程。
2.下载llama-factory的安装包
命令下载
git clone https://github.com/hiyouga/LLaMA-Factory.git直接下载压缩包
这里我是使用github压缩包的方式下载的文件(应为网络不好可能下载不下来)
执行安装命令
如果是下载源码包上传的,第一步需要解压压缩包(git clone下载的不需要)
unzip LLaMA-Factory-main.zip进入目录
cd LLaMA-Factory-main执行安装命令(注意最后有一个点)
pip install -e .安装完后执行启动webui命令
llamafactory-cli webui执行后看到这个就证明对了
running on local URL: http://0.0.0.0:7860吧AutoDl的端口映射到本地,这里面有详细的教程,自己去看吧。
访问后界面长这个样子
四、训练数据准备以及开始训练
上传训练数据
我在网上找了两个训练的文件,并改了一下。上传至llama_factory根目录下的data文件夹下LLaMA-Factory/data
可以直接拿来用,fintech文件数据有点多训练估计24G内存不太够
更改dataset_info
修改llama_factory数据文件LLaMA-Factory/data/dataset_info.json添加以下数据
"fintech": {
"file_name": "fintech.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
}界面化执行训练
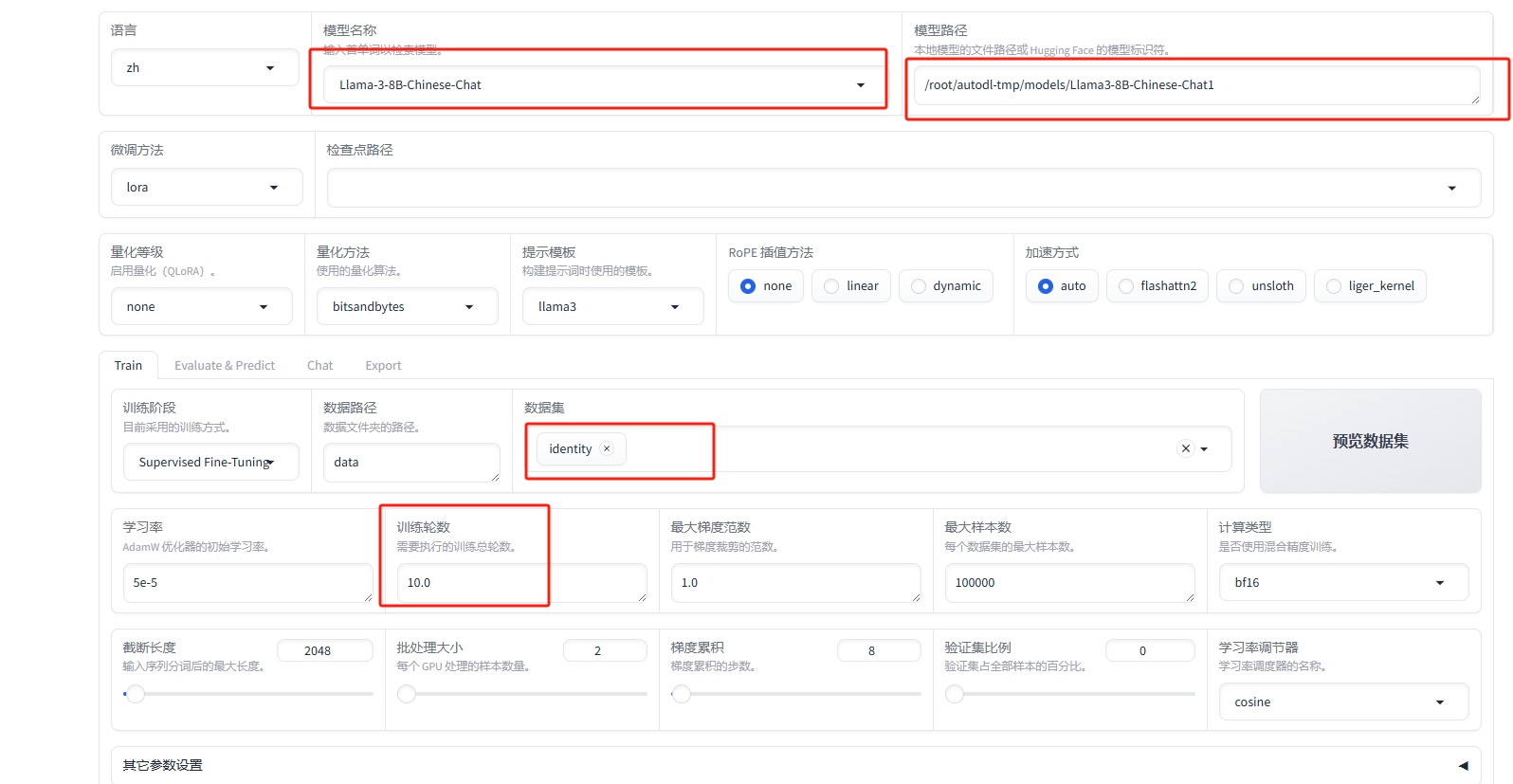
我更改了红色框中的数据,其他的没有动
模型名称:当前模型是什么名称
模型路径:在第二步中下载基座模型的就对路径
数据集:这里我只训练了identity,因为fintech大了点现存不够
训练轮次:从3改为了10,效果好一点
点击页面下方的开始,就开始了训练

在启用webui的控制台上能看到训练进度
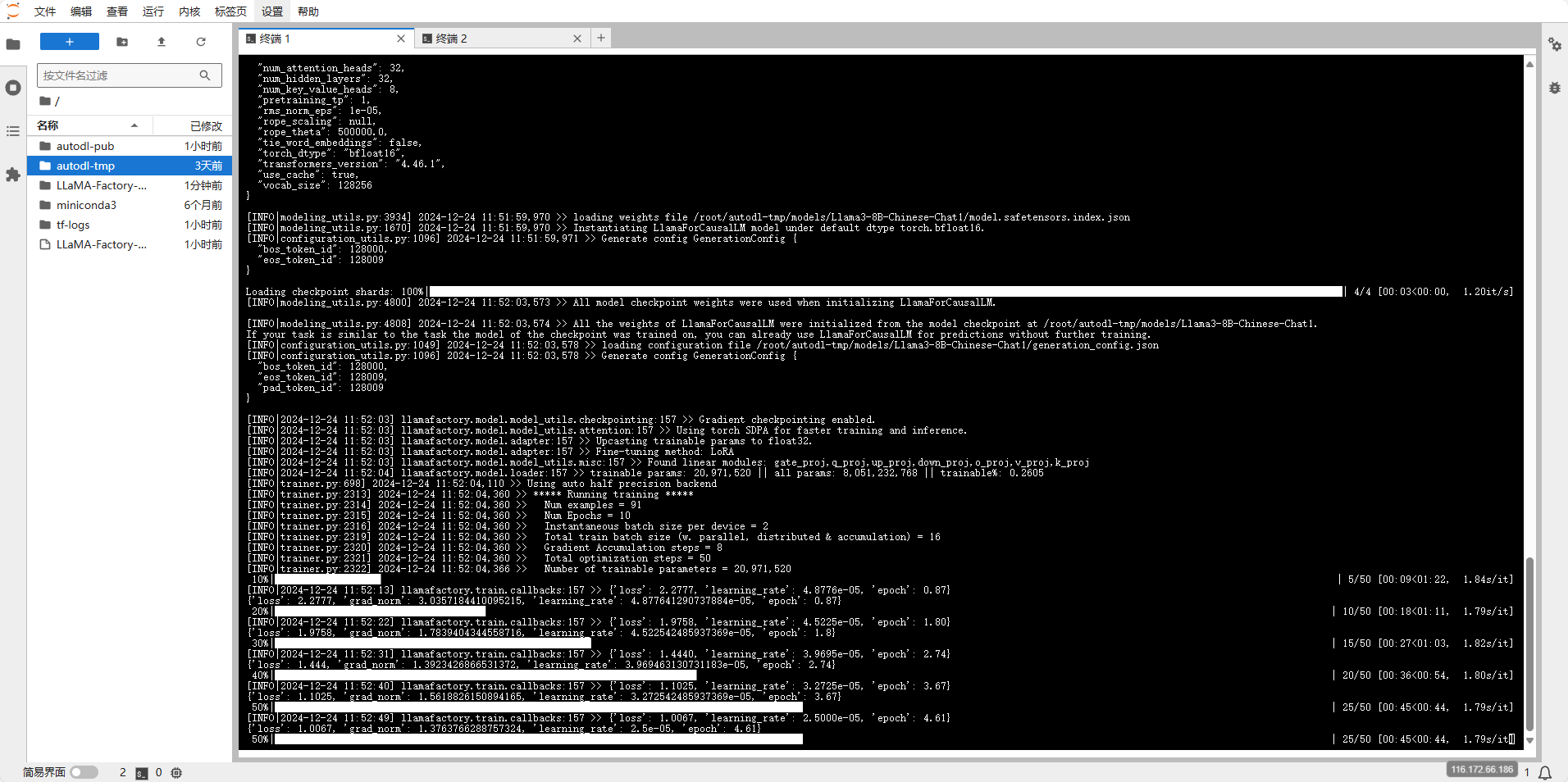
训练完成后,界面上会出现训练完成的提示
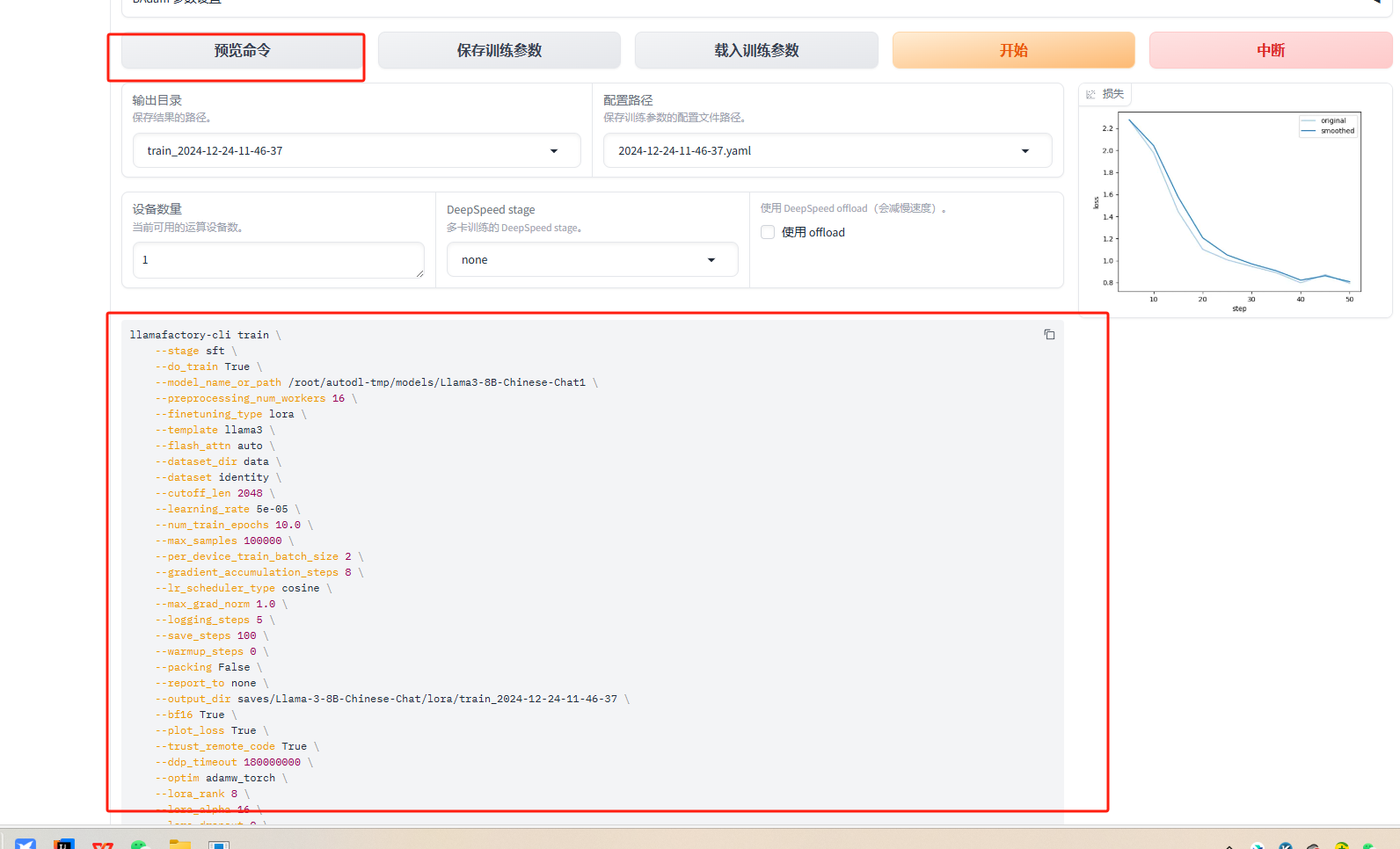
命令执行训练
使用命令训练有两种方法。
第一种是在webui上面设置好了参数,在下面点击预览命令,直接复制到命令行中运行
 2. 第二种方法,使用以下yaml模版更改参数后,保存在llama_factory根目录下的cust文件夹下
2. 第二种方法,使用以下yaml模版更改参数后,保存在llama_factory根目录下的cust文件夹下
例如:cust/train_llama3_lora_sft.yaml
cutoff_len: 1024
dataset: fintech,identity
dataset_dir: data
do_train: true
finetuning_type: lora
flash_attn: auto
fp16: true
gradient_accumulation_steps: 8
learning_rate: 0.0002
logging_steps: 5
lora_alpha: 16
lora_dropout: 0
lora_rank: 8
lora_target: q_proj,v_proj
lr_scheduler_type: cosine
max_grad_norm: 1.0
max_samples: 1000
model_name_or_path: /root/autodl-tmp/models/Llama3-8B-Chinese-Chat
num_train_epochs: 10.0
optim: adamw_torch
output_dir: saves/LLaMA3-8B-Chinese-Chat/lora/train_2024-05-25-20-27-47
packing: false
per_device_train_batch_size: 2
plot_loss: true
preprocessing_num_workers: 16
report_to: none
save_steps: 100
stage: sft
template: llama3
use_unsloth: true
warmup_steps: 0更改参数后,在llama_factory根目录下执行
llamafactory-cli train cust/train_llama3_lora_sft.yaml五、测试对话
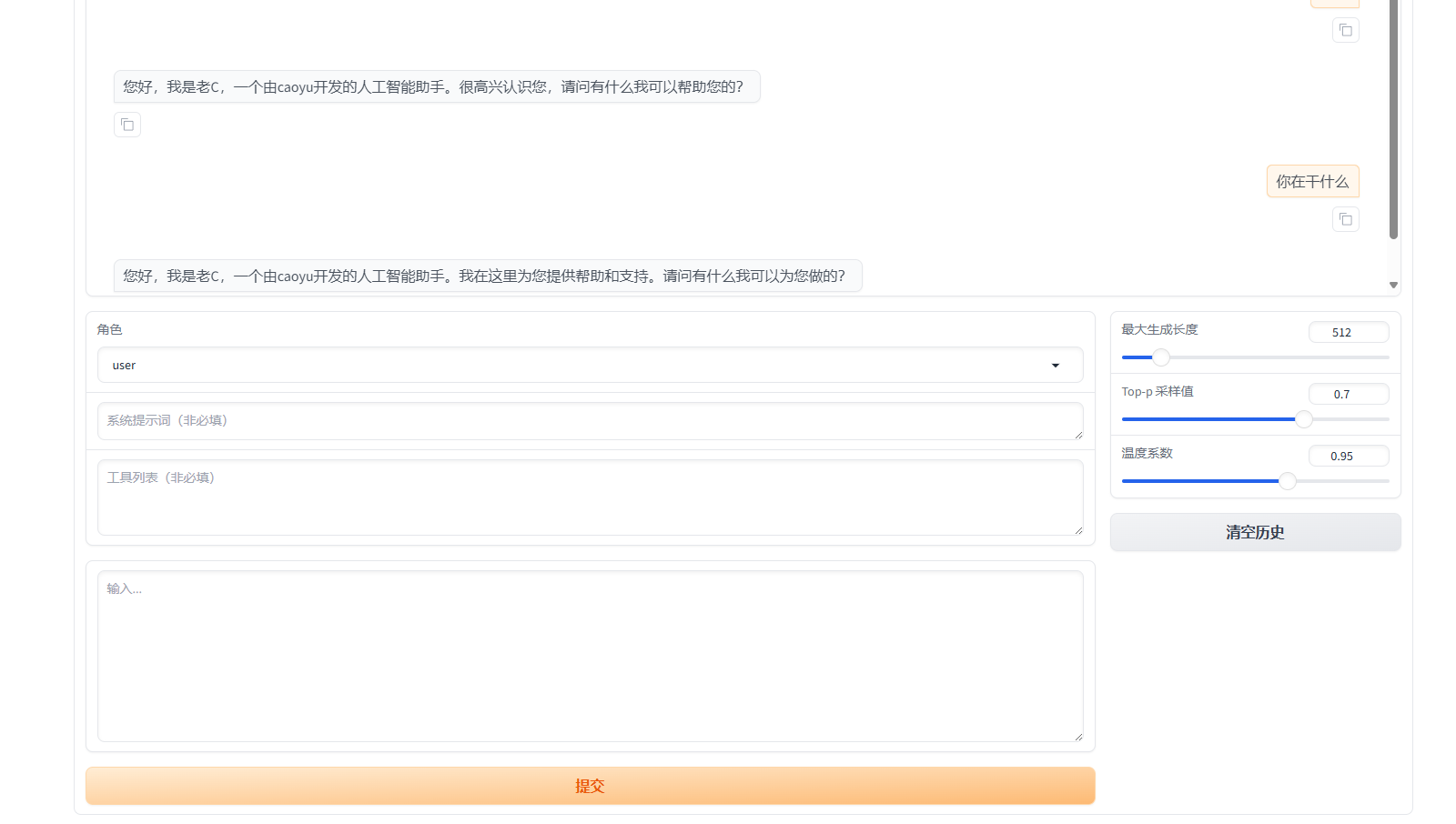
模型训练好了过后,可以使用webui上面的chat功能测试对话效果
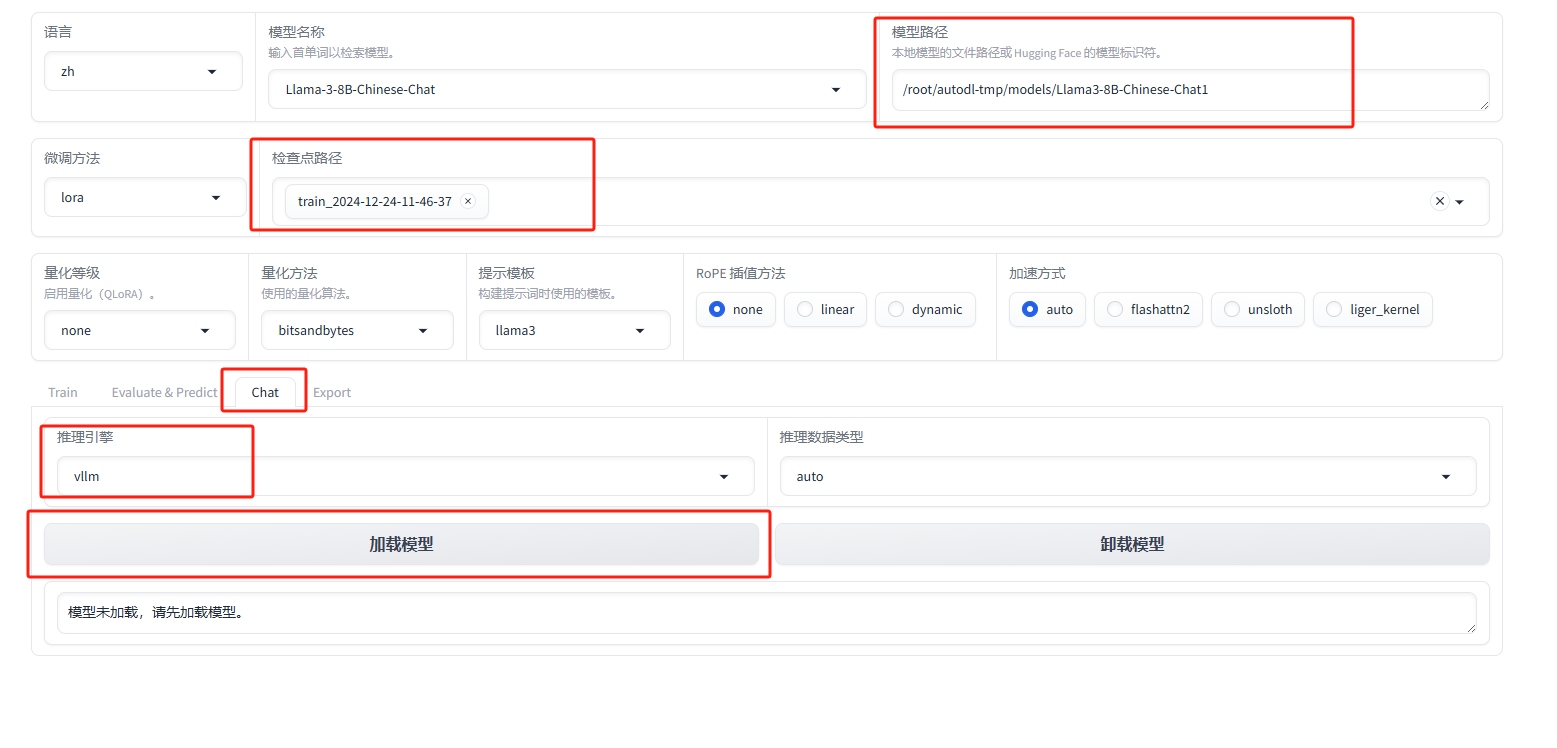
在界面上面选择相关信息,注意的是检查点路径需要选刚才训练好的路径,在点加载模型。
点加载后可能会报错
[INFO|modelcard.py:449] 2024-12-24 11:53:35,444 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}}
Traceback (most recent call last):
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/transformers/utils/versions.py", line 102, in require_version
got_ver = importlib.metadata.version(pkg)
File "/root/miniconda3/envs/factory/lib/python3.10/importlib/metadata/__init__.py", line 984, in version
return distribution(distribution_name).version
File "/root/miniconda3/envs/factory/lib/python3.10/importlib/metadata/__init__.py", line 957, in distribution
return Distribution.from_name(distribution_name)
File "/root/miniconda3/envs/factory/lib/python3.10/importlib/metadata/__init__.py", line 548, in from_name
raise PackageNotFoundError(name)
importlib.metadata.PackageNotFoundError: No package metadata was found for vllm
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/queueing.py", line 575, in process_events
response = await route_utils.call_process_api(
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/route_utils.py", line 322, in call_process_api
output = await app.get_blocks().process_api(
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/blocks.py", line 1935, in process_api
result = await self.call_function(
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/blocks.py", line 1532, in call_function
prediction = await utils.async_iteration(iterator)
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/utils.py", line 671, in async_iteration
return await iterator.__anext__()
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/utils.py", line 664, in __anext__
return await anyio.to_thread.run_sync(
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/anyio/to_thread.py", line 56, in run_sync
return await get_async_backend().run_sync_in_worker_thread(
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 2505, in run_sync_in_worker_thread
return await future
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/anyio/_backends/_asyncio.py", line 1005, in run
result = context.run(func, *args)
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/utils.py", line 647, in run_sync_iterator_async
return next(iterator)
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/gradio/utils.py", line 809, in gen_wrapper
response = next(iterator)
File "/root/LLaMA-Factory-main/src/llamafactory/webui/chatter.py", line 105, in load_model
super().__init__(args)
File "/root/LLaMA-Factory-main/src/llamafactory/chat/chat_model.py", line 49, in __init__
model_args, data_args, finetuning_args, generating_args = get_infer_args(args)
File "/root/LLaMA-Factory-main/src/llamafactory/hparams/parser.py", line 392, in get_infer_args
_check_extra_dependencies(model_args, finetuning_args)
File "/root/LLaMA-Factory-main/src/llamafactory/hparams/parser.py", line 125, in _check_extra_dependencies
require_version("vllm>=0.4.3,<0.6.5", "To fix: pip install vllm>=0.4.3,<0.6.5")
File "/root/miniconda3/envs/factory/lib/python3.10/site-packages/transformers/utils/versions.py", line 104, in require_version
raise importlib.metadata.PackageNotFoundError(
importlib.metadata.PackageNotFoundError: No package metadata was found for The 'vllm>=0.4.3,<0.6.5' distribution was not found and is required by this application.
To fix: pip install vllm>=0.4.3,<0.6.5这是因为vllm需要单独安装,这里看到LLaMA-Factory官网上说的版本号安装
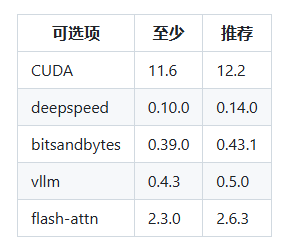
pip install vllm==0.5.0安装好后重启webui,在重新加载模型
六、合并
创建配置文件
新建一个配置文件:merge_llama3_lora_sft.yaml
### Note: DO NOT use quantized model or quantization_bit when merging lora adapters
### model
model_name_or_path: /root/autodl-tmp/models/Llama3-8B-Chinese-Chat1
adapter_name_or_path: /root/LLaMA-Factory-main/saves/Llama-3-8B-Chinese-Chat/lora/train_2024-12-24-11-46-37
template: llama3
finetuning_type: lora
### export
export_dir: /root/autodl-tmp/models/LLaMA3-8B-Chinese-Chat-merged
export_size: 4
export_device: cuda
export_legacy_format:需要更改
model_name_or_path:基座模型路径
adapter_name_or_path: 训练后模型的存放位置
export_dir: 输出合并模型的位置
执行合并命令
在llama_factory跟目录下执行
llamafactory-cli export merge_llama3_lora_sft.yaml完成~